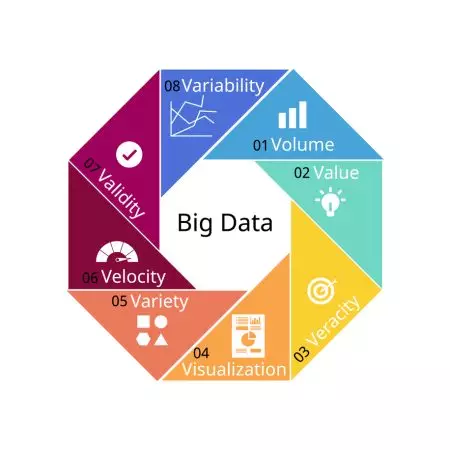
Il termine big data, al di là delle definizioni, è sempre correlato all’idea di un grande volume di dati che non è possibile elaborare e analizzare utilizzando metodi semplificati. Solitamente si tratta di dati che si presentano in molteplici varietà: strutturati, semi strutturati, non strutturati, legacy, provenienti da social media o generati da macchine.
La principale sfida del big data management è proprio riuscire a estrarre informazioni di valore per il business, da grandi volumi di dati che presentano strutture diverse.
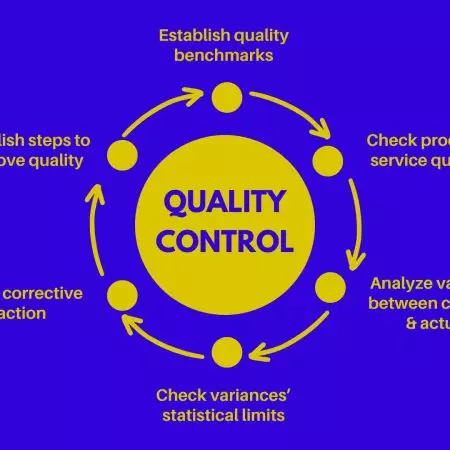
Per impostare una corretta strategia di big data management è bene porre l’attenzione su alcuni aspetti fondamentali.
Il valore delle competenze
In una strategia di gestione dei big data è essenziale ricordare che non serve a nulla acquisire più dati se poi non si è in grado di estrarne informazioni da trasformare in risultati di business. Perseguire quest’ultimo obiettivo richiede la partecipazione di figure professionali di nuovo tipo. Accanto ai data scientist, capaci di organizzare grandi set di dati, assume un’importanza crescente la presenza di professionisti con avanzate competenze matematiche, in grado di produrre rappresentazioni logico-matematiche del know-how aziendale e di integrarle all’interno di modelli sviluppati ad-hoc.
La disponibilità di nuovi “skill” non è, tuttavia, ristretta solo ai tecnologi.
Anche gli esperti e i decisori devono “reinventarsi” perché l’uso di strumenti innovativi di analisi, infatti, non elimina l’intervento umano e la sua capacità di analisi; anzi, lo potenzia e lo esalta. Per poter compiere scelte più motivate e pertinenti è necessario, tuttavia, rafforzare la capacità di districarsi tra i big data, di effettuare le corrette operazioni di ricerca e visualizzazione e acquisire nuove capacità di analisi e interpretazione dei risultati estratti dai dati.
La competenza è la leva abilitante per attuare processi di rinnovamento dei modelli di business e dei processi che li sostengono.
I processi
Peraltro, l’esigenza di rispondere in tempi sempre più rapidi alle spinte del mercato e di adeguarsi alle richieste dei clienti, in uno scenario caratterizzato dal costante cambiamento, richiede una digitalizzazione sempre più spinta dei processi. Solo così, infatti, diviene possibile predisporre i meccanismi di automazione e ottimizzazione necessari per conseguire gli obiettivi di business e, nel contempo, verificare costantemente che le azioni strategiche e di business siano allineate tra loro e con le richieste dei clienti. Tutto ciò richiede una visione congiunta da parte delle persone coinvolte e induce a massimizzare la cooperazione tra chi gestisce i dati (competente nelle tecniche di estrazione dei risultati) e chi li utilizza (competente nelle questioni di business).
Gli aspetti tecnologici
Certamente, la gestione dei big data richiede anche l’adozione di una pluralità di tecnologie. Alcune di queste vengono dal mondo “tradizionale” della modellazione e architettura dei dati e sono state raffinate e migliorate negli ultimi anni per rispondere alle esigenze di interagire con i big data. Tra queste ricordiamo, per esempio, le tecniche di data mining che permettono di individuare “pattern” non immediatamente visibili all’interno di grandi set di dati coniugando metodi di machine learning, statistica e analytics.
Altri esempi comprendono l’uso di algoritmi genetici per risolvere problemi di ottimizzazione non lineare dei processi, o l’utilizzo di reti neurali per far emergere in modo automatico le relazioni input-output soggiacenti processi di grande complessità.
A queste tecnologie se ne sono aggiunte altre, di nuova concezione, focalizzate sugli aspetti di individuazione, analisi e automazione dei dati e sull’elaborazione di modelli. Altrettanto importante è l’individuazione del linguaggio da utilizzare per la data analysis, per esempio tra Python e R. Entrambi, infatti, sono adatti per ogni compito legato alla data science e la decisione andrà presa in base alla tipologia di problemi da affrontare, ai compiti da svolgere, alla competenza sullo specifico linguaggio presente in azienda e all’integrabilità con gli strumenti preesistenti. Tra gli aspetti essenziali da considerare in un processo di big data management possiamo annoverare:
- La capacità di acquisire dati da fonti note e attendibili, di filtrare quelli utili al business, di archiviarli in modo centralizzato e di stabilirne la qualità in relazione al valore per il business;
- L’uso di strumenti per il pretrattamento di dati eterogenei, in grado di modificarli per renderli confrontabili senza perdere, nel processo, parte dell’informazione;
- La scelta dell’architettura hardware e software più adatta a elaborare i dati, trasferirli, condividerli e archiviarli;
- La capacità di definire modelli adatti a specifici “use case ” e di preparare set di dati per alimentarli correttamente;
- La disponibilità di strumenti per visualizzare in modo semplice e intuitivo i risultati, mettendo a disposizione del decisore tutte le informazioni necessarie per per una migliore comprensione dei criteri che hanno portato al risultato finale.
La cultura aziendale e l’effetto ippopotamo
Un ultimo aspetto di cui tenere conto nella strategia di big data management è legato alla predisposizione di una cultura aziendale coerente con i principi “data-driven”.
Questo significa evitare di basare la strategia unicamente sulle intuizioni dei manager e smettere di usare l’approccio che gli anglosassoni chiamano “effetto ippopotamo”. Una definizione che trae origine dall’acronimo HiPPO (highest paid person’s opinion), che sottolinea l’attitudine a ignorare le evidenze associate alla quantità e qualità dei dati disponibili.
Contattaci per ricevere ulteriori informazioni